【原理分析】Redis为什么这么快?
上来就先来一张图,很快啊,马上就就能看懂
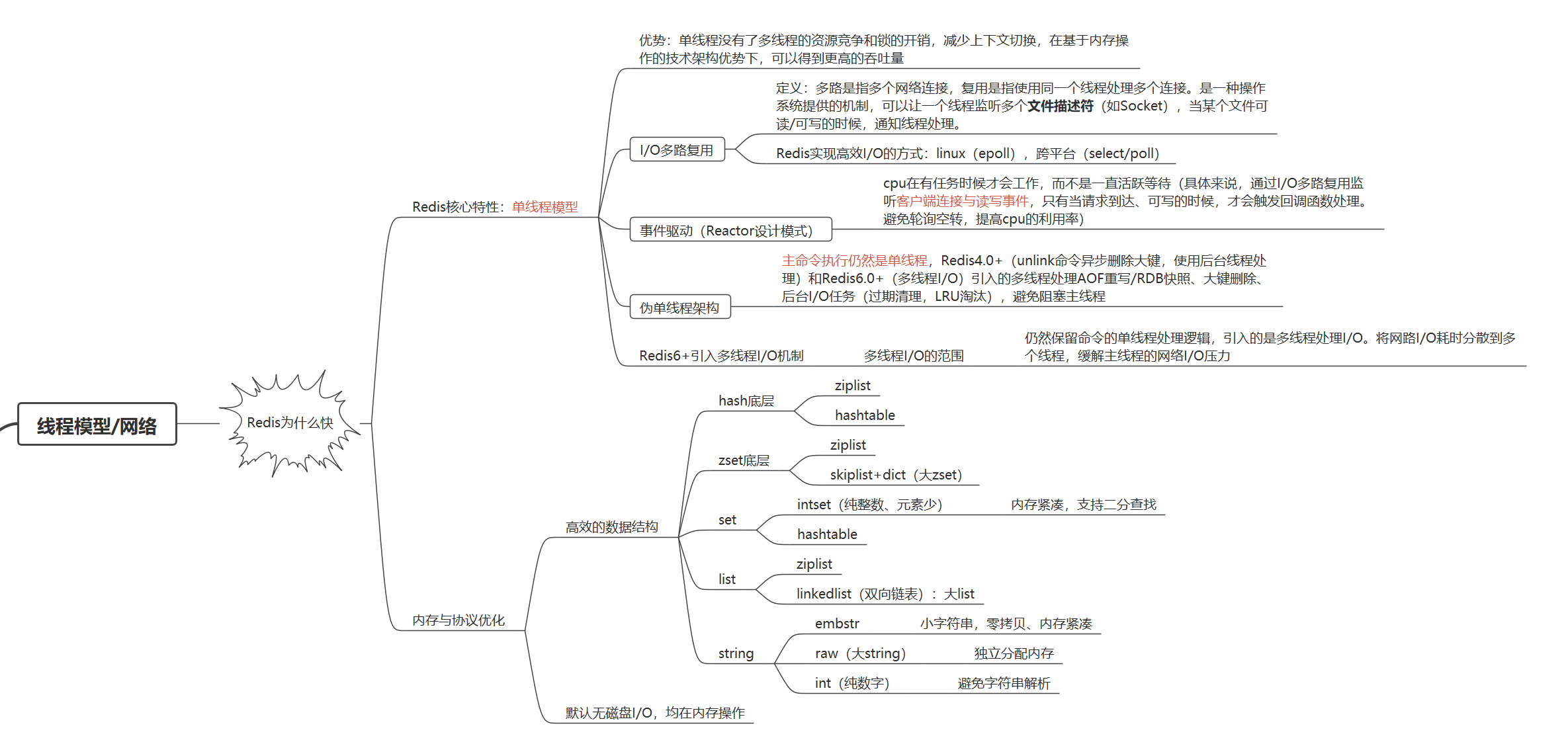
一、线程模型 / 网络层(单线程 + I/O 多路复用)
Redis 的“快”,首先体现在其极简高效的网络处理架构上。
1. Redis 核心特性:单线程模型
- 优势:
- 避免多线程资源竞争、锁开销、上下文切换。
- 基于内存操作,指令流水线效率高,缓存局部性好。
- 在高并发下仍能保持稳定吞吐量。
注意:Redis 的“单线程”指的是命令执行是单线程串行处理,而非所有操作都单线程。
2. I/O 多路复用(核心支撑高并发)
定义:
多路指多个网络连接;复用指使用同一个线程处理多个连接。操作系统提供机制,允许一个线程监听多个文件描述符(如 Socket),当某个可读/可写时通知线程处理。
Redis 实现方式:
- Linux:
epoll - macOS/BSD:
kqueue - 跨平台兼容:
select/poll(性能较差,仅作兜底)
- Linux:
作用:
- 单线程可同时服务成千上万客户端连接。
- 避免阻塞等待,CPU 利用率高。
3. 事件驱动架构(Reactor 模式)
工作原理:
CPU 只在有任务时才工作 —— 通过 I/O 多路复用监听客户端连接与读写事件,只有当请求到达或可写时才触发回调函数处理。
优势:
- 避免轮询空转,提高 CPU 利用率。
- 所有操作注册在事件循环中,逻辑清晰、响应及时。
4. “伪”单线程架构(Redis 4.0+ / 6.0+ 引入异步/多线程)
Redis 并非完全单线程,而是主命令执行单线程 + 后台任务/网络 I/O 多线程。
Redis 4.0+ 引入:
UNLINK命令:异步删除大 key,避免阻塞主线程。- AOF 重写、RDB 快照:子进程执行(fork),不影响主线程。
Redis 6.0+ 引入:
多线程 I/O(默认关闭):
仅用于网络读写阶段(read/write client socket)。
命令解析、执行、数据操作仍由主线程完成,保证原子性和一致性。
配置参数:
1
2io-threads-do-reads yes
io-threads 4
适用场景:
- 高并发、大流量环境(如千兆网卡),可提升 2~3 倍吞吐量。
- 小并发下建议关闭,避免线程切换开销。
二、高效的数据结构(Redis 性能之魂)
Redis 的“快”,本质源于其为每种数据类型精心设计的底层数据结构。这些结构在空间、时间复杂度上做了极致优化,并支持自动切换,用户无感知。
1. String 类型
| 编码方式 | 适用场景 | 特点 |
|---|---|---|
embstr |
小字符串(≤44 字节) | 分配在一块连续内存,零拷贝、内存紧凑 |
raw |
大字符串 | 独立分配内存,支持任意长度 |
int |
纯数字字符串 | 直接存储整数,避免字符串解析,加速 INCR/DECR |
优势:小字符串高效,数字操作无解析开销。
2. Hash 类型
| 编码方式 | 适用场景 | 特点 |
|---|---|---|
ziplist |
元素少、key/value 短 | 内存紧凑,连续存储,节省空间 |
hashtable |
元素多或 value 长 | O(1) 查找,适合大数据量 |
自动转换配置:
1 | |
优势:小 hash 内存占用比 hashtable 小 50% 以上。
3. List 类型
| 编码方式 | 适用场景 | 特点 |
|---|---|---|
ziplist |
元素少、value 短 | 内存紧凑 |
linkedlist |
元素多 | 双向链表,O(1) 头尾插入 |
quicklist(推荐) |
所有场景 | ziplist 的链表组合,兼顾内存与速度 |
quicklist 优势:
- 每个节点是一个 ziplist,控制大小(默认 8KB),避免复制开销。
- 支持 O(1) 头尾操作,O(n) 中间查找(但实际很少用)。
配置:
1 | |
4. Set 类型
| 编码方式 | 适用场景 | 特点 |
|---|---|---|
intset |
全是整数、元素少 | 内存紧凑,支持二分查找 O(log n) |
hashtable |
含非整数或元素多 | O(1) 查找 |
自动转换配置:
1 | |
优势:整数集合内存节省 3~5 倍,查询高效。
5. ZSet(有序集合)
| 编码方式 | 适用场景 | 特点 |
|---|---|---|
ziplist |
元素少、score/member 短 | 内存紧凑 |
skiplist + dict |
元素多 | 跳表支持 O(log n) 插入/删除/范围查询,哈希表支持 O(1) 按 member 查 score |
为什么用跳表?
- 实现简单,无需 B+ 树复杂的平衡操作。
- 支持高效范围查询(ZRANGE)。
- 与哈希表结合,满足多种访问模式。
配置:
1 | |
三、内存与协议优化
Redis 的“快”,还体现在其纯内存操作 + 零拷贝优化 + 协议简洁。
1. 默认无磁盘 I/O,均在内存操作
- 所有数据存储在内存,读写速度极快。
- 持久化(RDB/AOF)是后台异步进行,不影响主线程。
* 2. 协议简洁(RESP 协议)
- 客户端与服务器通信使用 RESP(REdis Serialization Protocol),文本协议,解析简单。
- 命令格式统一
- 解析速度快,无复杂序列化开销。
3. 零拷贝与内存紧凑设计
embstr、ziplist、intset等结构尽量连续存储,提高缓存命中率。quicklist分块设计,避免大 ziplist 修改时的复制开销。
【原理分析】Redis为什么这么快?
http://example.com/2025/10/04/Redis_sofast_why/